


Why Apache Spark on K8s?
Apache Spark is a widely recognized and extensively used distributed processing engine, particularly in handling big data. Enterprises typically employ it to manage and process their business-critical data at scale and extract valuable analytics that offers actionable insights and strategic advantages. It offers a programming interface for achieving data parallelism and ensuring fault tolerance.
Spark was widely used on top of Hadoop (HDFS) and is a well-established technology among enterprises. However, industries are now shifting towards containerization. Apache Spark has also adapted to this trend by supporting Kubernetes-based deployments to achieve the same.
The combination of Apache Spark and Kubernetes offers a compelling solution for organizations that require powerful data processing capabilities along with efficient resource management. Here’s why this duo is so powerful:
- Scalability: Both Spark and Kubernetes are designed to scale. Kubernetes can easily manage the computing resources that Spark requires for its data-intensive tasks. You can automatically scale your Spark applications up or down based on the workload, ensuring optimal resource utilization.
- Resource Efficiency: Kubernetes provides more efficient resource management compared to standalone Spark clusters or even Spark on YARN. This is due to Kubernetes’ more advanced scheduling capabilities and its ability to share resources between Spark and other applications running in the same cluster.
- Unified Management: Running Spark on Kubernetes allows you to manage both your data processing workloads and other microservices workloads in a unified manner. This results in a simplified operational experience and can lower the overall total cost of ownership.
Why Managing Spark on Kubernetes is Non-Trivial?
While the advantages of running Apache Spark on Kubernetes are significant, implementing and managing this setup can be quite complex. Operationalizing Spark in a K8 environment, especially at scale, poses challenges for enterprises. Here are some of the major hurdles:
Building Spark applications for Kubernetes:
- Containerization: Spark applications must be containerized to run on Kubernetes. While docker simplifies this process to some extent, configuring docker images correctly for Spark can be intricate.
- Dependencies: Managing dependencies for Spark applications can become complex, particularly when integrating with storage systems, databases, or additional libraries.
- Configuration mismatch: Ensuring that Spark configurations align with the K8s cluster settings is crucial, but can also be error-prone
Deploying and Managing Spark Applications:
- Resource allocation: Determining the right amount of resources (CPU, memory, storage) for each component (Driver, Executors) can be a delicate balancing act.
- Job scheduling: While Kubernetes excels in microservices, its job scheduling capabilities may not be fully optimized for long-running data processing tasks. This may require additional configuration and tuning.
- Zero touch pod scheduling: For enterprises, leveraging smart scheduling capabilities to efficiently utilize resources when running Spark on Kubernetes can be challenging. This is especially true when dealing with hundreds of jobs running simultaneously in a cluster.
Monitoring and Logging:
- Metrics overload: Both Spark and Kubernetes generate an abundance of metrics, and identifying the ones crucial for your application’s performance can be overwhelming.
- Log management: Spark applications produce extensive logs. Aggregating, storing, and analyzing these logs in a Kubernetes environment require additional tools and configurations.
- Visibility: Kubernetes’ abstraction layers can sometimes obscure the process of debugging and tracing issues in a Spark application, particularly concerning network traffic and storage access.
As both Spark and Kubernetes have extensive and fast-evolving ecosystems, keeping up with best practices, updates, and new features for both can be a time-consuming endeavor.
While each of these challenges is surmountable, they do introduce additional layers of complexity that organizations must carefully consider. Successful management of Spark applications on a Kubernetes cluster necessitates proper planning, skilled personnel, and the right set of tools.
Introducing SparkOps: The Unified Solution for Spark on Kubernetes
After gaining insights into the complexities and challenges of managing Apache Spark on Kubernetes, it’s time to introduce a game-changing solution: SparkOps by DataByte solutions. Designed as a unified data engineering platform, SparkOps addresses the pain points associated with building, deploying, managing, and monitoring Spark applications on Kubernetes.
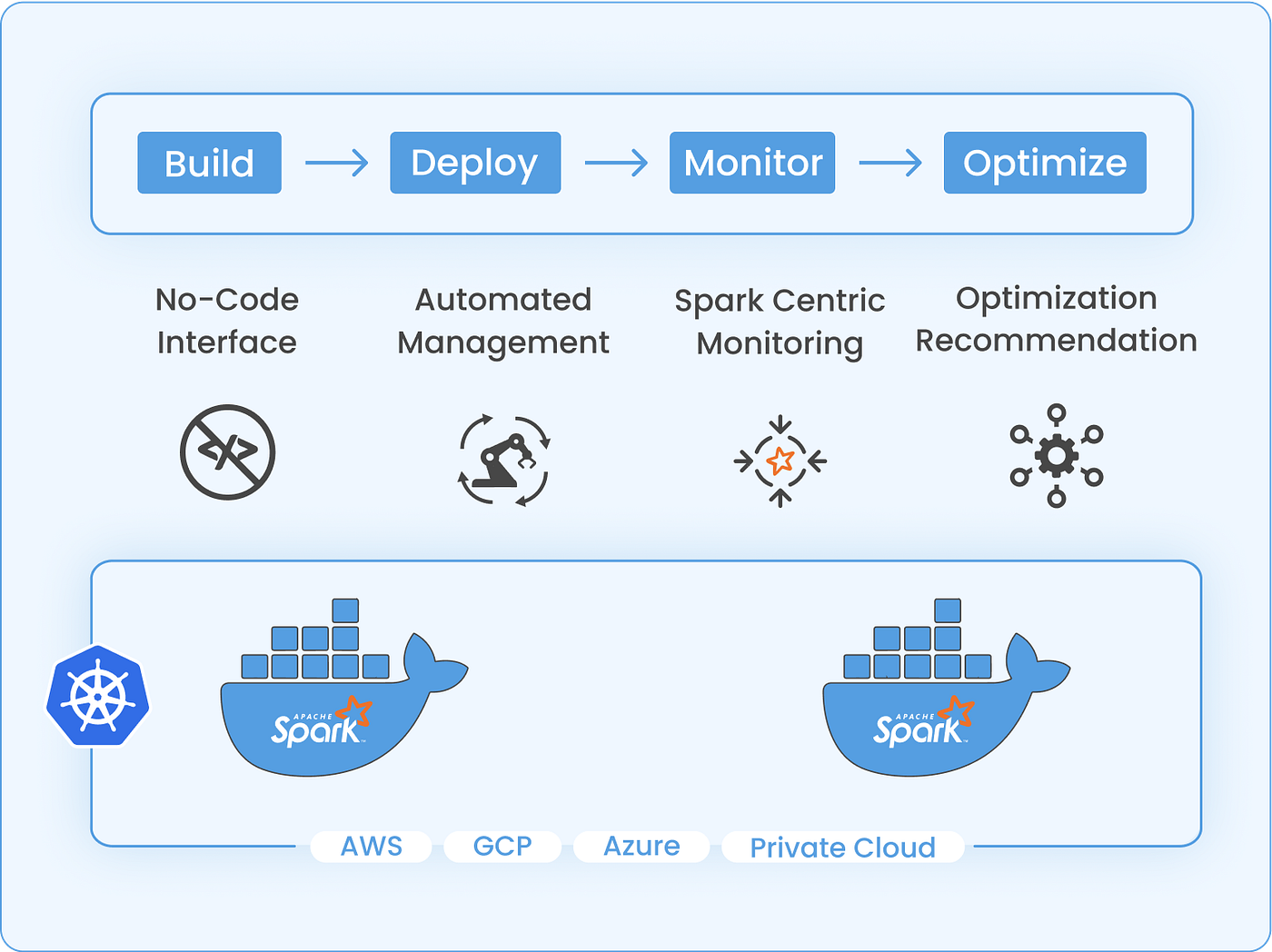
Built for Everyone in the Enterprise
For Developers:
- 🛠 No-Code Intuitive UI: Easily create, test, and deploy Spark jobs without the need to write a single line of code.
- 📦 Extensive Connector Support: Seamlessly integrate with a wide range of data sources and sinks, including databases and cloud storage solutions…
For Operations Teams:
- 📊 Single Pane of Operations Dashboard: Gain comprehensive insights with a unified dashboard that provides visibility into cluster health, resource utilization, and predictive analytics for future requirements.
- 🛠 Spark-Centric Monitoring and Logging: Easily access all essential metrics and logs customized for Spark environments.
For Management:
- 📈 Resource Planning Tools: Gain insights and plan cluster resources based on real utilization data, enabling more effective budget allocation and infrastructure planning.
- 📈 Focus on Business, Not Just Operations: With features such as a no-code UI and built-in security, your teams can focus on delivering business value rather than being overwhelmed by operational complexities.
Core Features
Multi-Cluster Smart Orchestration: Achieve zero-touch automation for managing multiple clusters, ensuring high availability and fault tolerance with geographic redundancy.
Built-in Data Governance: Automatically adhere to data compliance and regulatory standards without the need for external tools.
Security and Authorization: Benefit from robust built-in security measures, including role-based access controls and encryption.
Optimization Recommendations: Leverage intelligent analytics to receive optimization suggestions for your Spark deployments, enabling your teams to prioritize data processing tasks over performance tuning.
Ready to simplify your Spark on Kubernetes journey?
Managing Apache Spark on Kubernetes doesn’t have to be complicated. With SparkOps, you gain access to a unified platform that removes the complexity from Spark deployment, management, and optimization. Experience the simplicity of big data processing like never before, with every feature crafted to meet the needs of developers, operations teams, and management alike.

